我给你讲,淀粉质可好吃了,真的
点分治,是一种处理树上路径问题的工具,举个例子:
给定一棵树和一个整数$k$,求树上等于$k$的路径有多少条
做法很简单,枚举不同的两个点,然后$dfs$算出ta们间的距离,统计一下就行了
大概是$O(n^3)$的复杂度
布星啊$n$大一点就搞不了了
那找个根,求出每个点到根的距离,然后枚举两个点,求$lca$,简单加减一下就行了
大概是$O(n^2\log n)$的复杂度……?
还是布星啊我$n$还要大,几万的数据就搞不了了怎么这么多事
考虑一下形成路径的情况,假设一条满足条件的路径经过点$x$,那么这条路径在$x$的一个子树里(以$x$为端点)或者在$x$的两个不同的子树里,如图:
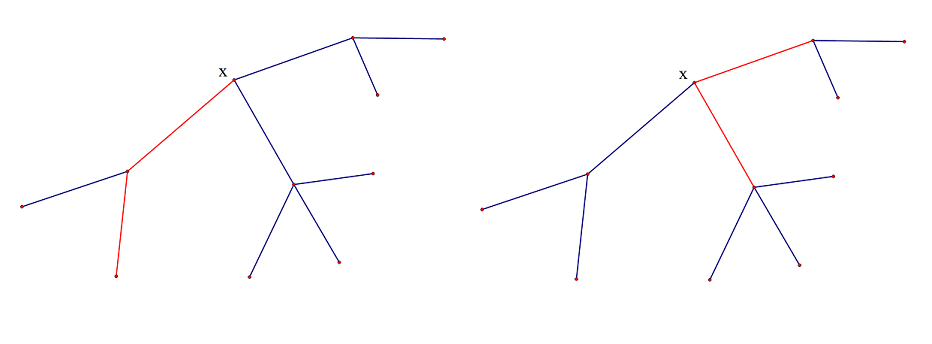 一个好的想法是找到一个根,然后$dfs$遍历ta子树中的每个点,依次处理每个点的子树答案
一个好的想法是找到一个根,然后$dfs$遍历ta子树中的每个点,依次处理每个点的子树答案
-
原理
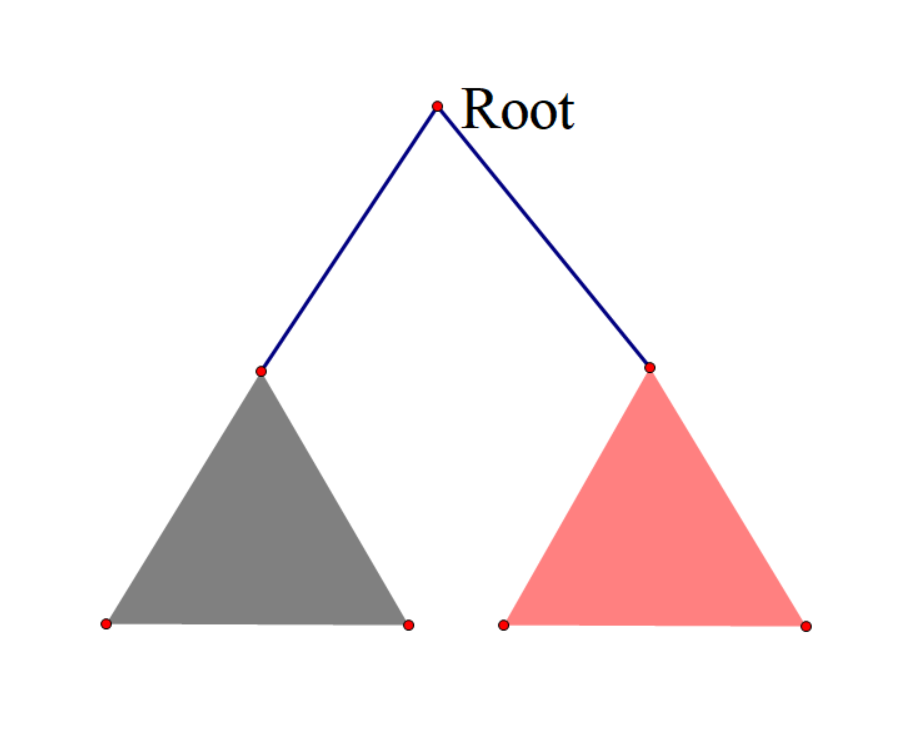
如图,假设我们选出一个根$Root$,那么答案路径肯定是要么被一个子树所包含,要么就是跨过$Root$,在黑子树中选择一部分路径,在红子树中选择一部分路径,然后从$Root$处拼起来形成一条答案路径
两种情况诶……分类讨论?
分类讨论不会写的,这辈子都不可能写分类讨论的
仔细想一下,发现情况$1$(被一个子树包含)中,答案路径上的一点变为根$Root$,就成了情况$2$(在两棵子树中)
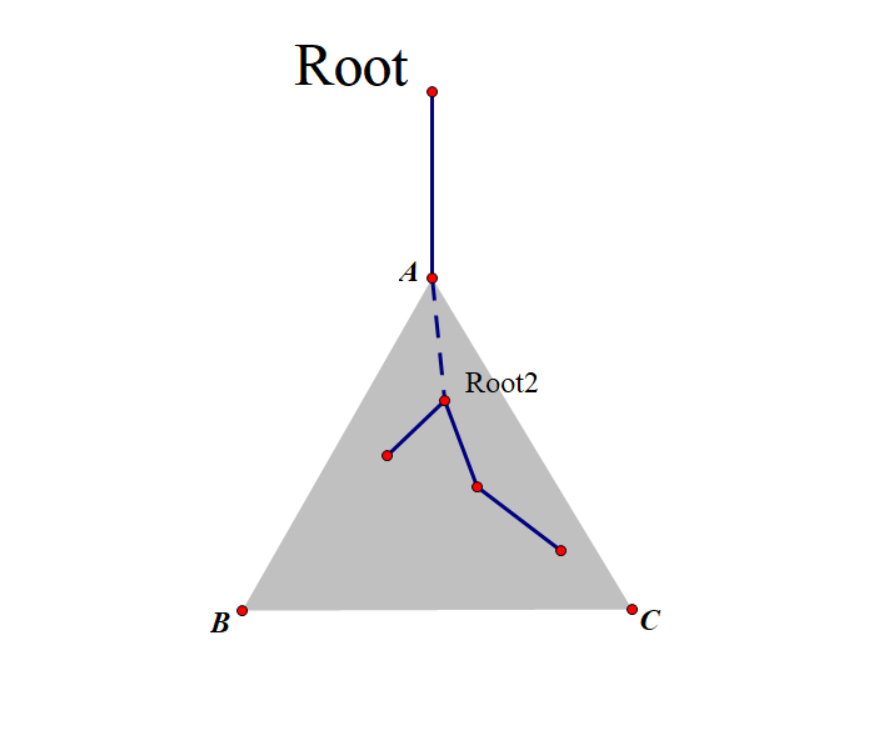
如图,$Root$为根的子树中存在答案(蓝色实边路径),可以看成以$Root2$为根的两棵子树存在答案,所以只用处理情况$2$就行了,可以用分治的方法,这应该是点分治的基本原理
先从找好一个根开始
-
选根(选重心)
首先根不能随便选,选根不同会影下面遍历的效率的,如图:
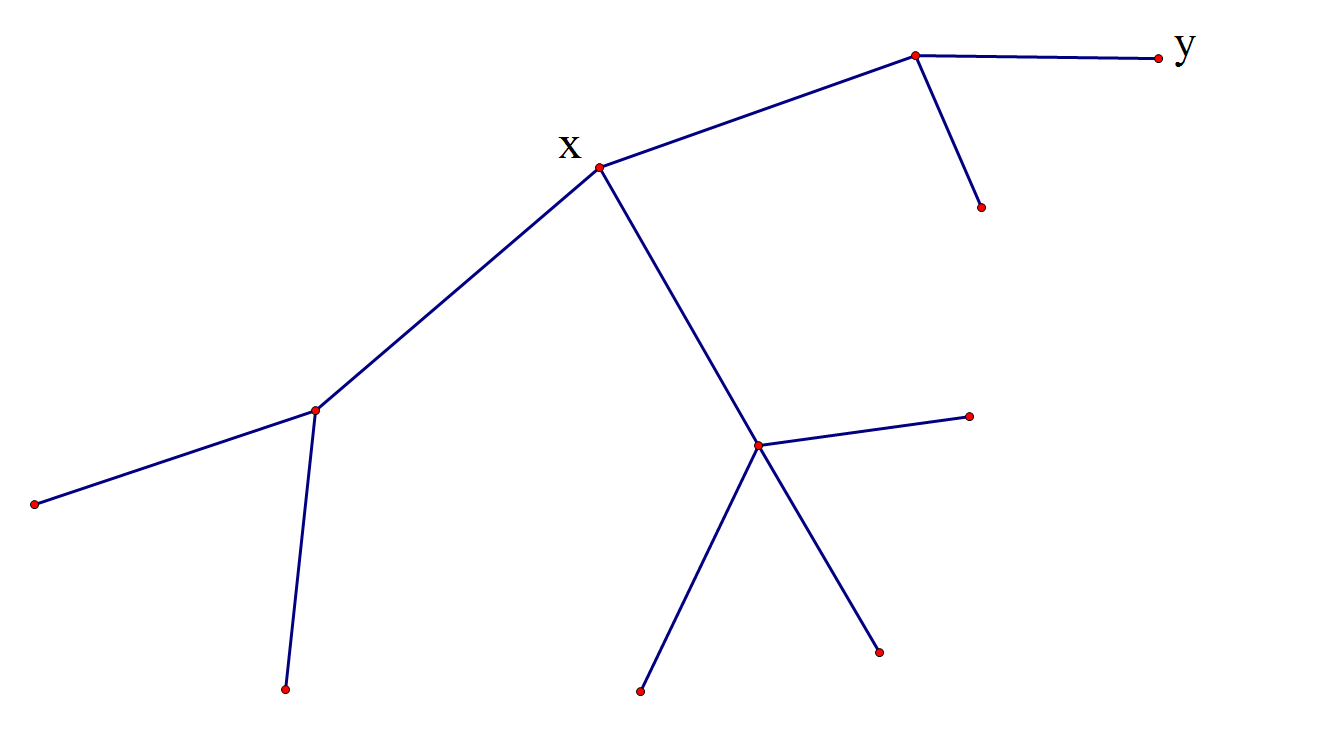
显然选$y$为根比选$x$为根不优,选$x$最多递归$2$层,选$y$最多递归$4$层
显然可以发现找树的重心(重心所有的子树的大小都不超过整个树大小的一半)是最优的
我们可以根据每个点子树大小确定根,当根的最大的子树最小时肯定是重心
一个简单的树形$dp$就能搞定
void GET_ROOT(int x,int fa)//x为当前点,fa为父亲节点
{
f[x]=0,siz[x]=1;//f表示这个点最大子树的大小,siz是这个点子树大小的和
for(int i=h[x];i;i=c[i].x)//枚举儿子
{
int y=c[i].y;
if(use[y]||y==fa) continue;//use表示之前遍历过了,这里没啥用
GET_ROOT(y,x);//往下遍历
f[x]=max(f[x],siz[y]);//更新f
siz[x]+=siz[y];
}
f[x]=max(f[x],Siz-siz[x]);//Siz表示在现在这棵子树中点的总数,开始时Siz=n,除了枚举的儿子所在的子树外,还有一棵子树是上面的那一堆,容斥原理
if(f[x]<f[rt]) rt=x;//更新root
}
因为之后的分治过程还需要对子树单独找重心,所以代码中有$use$,但是开始对整棵树无影响
-
求距离
找到根了,现在我们可以$dfs$一遍重心的子树,求出重心到子树各个点的距离
然后可以枚举子树里的两个点,如果两个点到重心的距离和为$k$(题目要找距离为$k$的点对),那么答案$+1$
这是第二种情况,第一种情况就让距离根为$k$的点跟重心配对就行了,因为重心到重心的距离为$0$
如何统计答案呢?
-
统计答案
肯定不能直接枚举啊……$n^2$的复杂度啊喂
考虑枚举一个点,另一个点可以通过二分来求解,$sort$一下让距离有序,这样要找距离为$k-$枚举点的距离的点的个数,因为相同距离的点现在是连续的,所以可以二分出左右边界$l,r$,$ans+=r-l+1$
int look(int l,int x)//找左边界
{
int ans=0,r=cnt;
while(l<=r)
{
int mid(l+r>>1);
if(d[mid]<x) l=mid+1;
else ans=mid,r=mid-1;
}
return ans;
}
int look2(int l,int x)//找右边界
{
int ans=0,r=cnt;
while(l<=r)
{
int mid(l+r>>1);
if(d[mid]<=x) ans=mid,l=mid+1;
else r=mid-1;
}
return ans;
}
void GET_NUM(int x,int fa,int D)//求重心到子树每个点的距离
{
for(int i=h[x];i;i=c[i].x)
{
int y=c[i].y;
if(use[y]||y==fa) continue;
d[++cnt]=D+c[i].dis;
GET_NUM(y,x,d[cnt]);
}
}
int GET_ANS(int x)//求答案
{
d[cnt=1]=0;
GET_NUM(x,0,0);
sort(d+1,d+1+cnt);//排下序
int l=1,ans=0;
while(l<cnt&&d[l]+d[cnt]<k) ++l;
while(l<cnt&&k-d[l]>=d[l])
{
int D1=(look(l+1,k-d[l])),D2=(look2(l+1,k-d[l]));//枚举一个点,因为和是k,所以可以直接求出另一点到重心的距离,二分一下就行了
if(D2>=D1) ans+=D2-D1+1;
++l;
}
return ans;
}
void dfs(int x)//分治函数
{
use[x]=1,ans+=GET_ANS(x);//统计这个点的答案
for(int i=h[x];i;i=c[i].x)
{
int y=c[i].y;
if(use[y]) continue;//防止找父亲
Siz=siz[y],rt=0;//下一个重心肯定在当前点的子树里
GET_ROOT(y,x),dfs(rt);//找下一个重心
}
}
也可以通过移动两个指针来实现只要不是枚举两个点就行了
这样我们就快乐的A掉了这道题

了吗?
求一遍发现答案不对诶……似乎多了几种情况?如图:
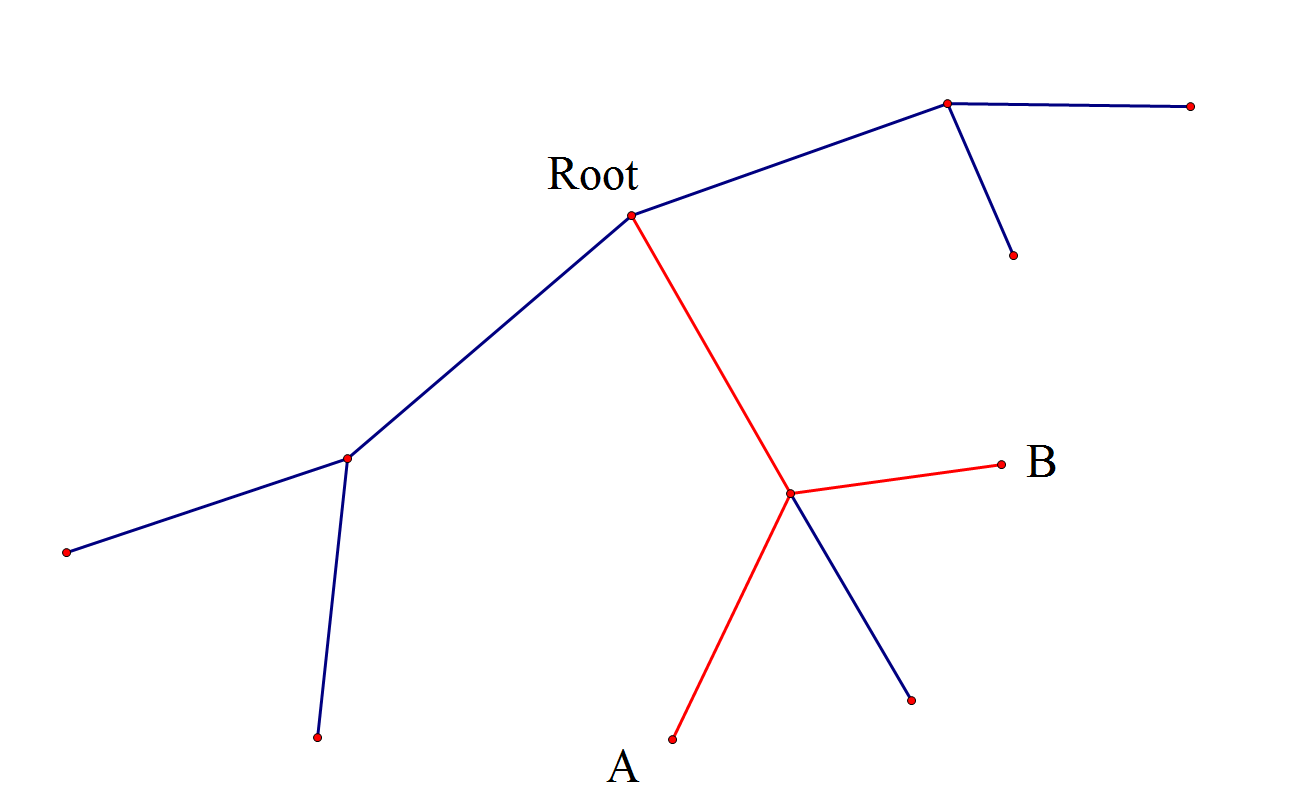
假设$k=4$,图中$A$到$Root$的距离为$2$,$B$到$Root$的距离为$2$,合起来是$4$,这时候答案$+1$,但是显然这两个点最短路径不是$4$
这是因为ta们在同一子树中,到重心的路径有重叠部分
-
统计答案 二连击
处理方法:
1.可以求距离的时候把点染色,不同子树不同颜色,那么求答案的时候就得枚举每个符合答案的每个点看是否不在一个子树里
2.可以求当前点儿子的答案,统计儿子答案时各个点的距离加上儿子到根的距离,即把符合在一个子树条件的情况统计出来,最后这个点的答案减去儿子答案就行了
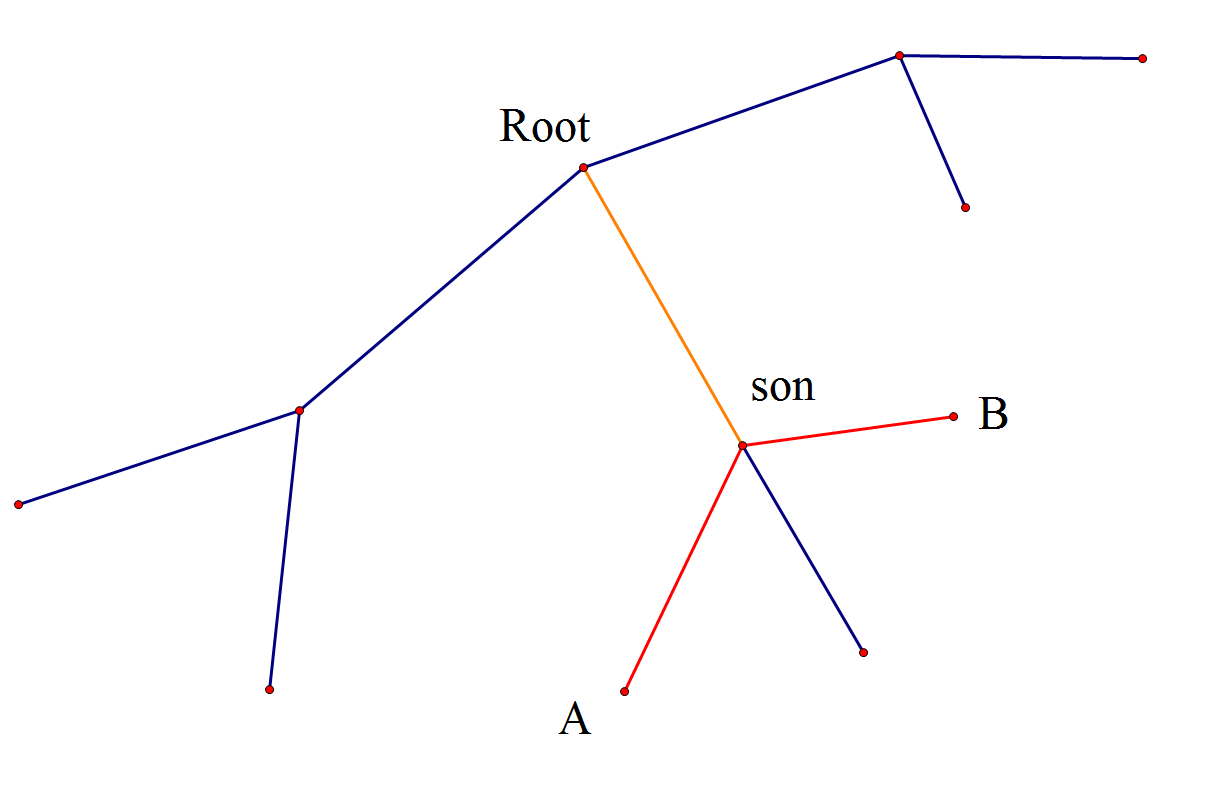
图中求$Root$儿子$son$的答案,因为加上儿子到重心的距离,所以$A$的距离还是$2$,$B$的距离还是$2$,这样就把不符合条件的答案去掉了
int GET_ANS(int x,int D)//改一下这里就行了
{
d[cnt=1]=D;
GET_NUM(x,0,D);
sort(d+1,d+1+cnt);
int l=1,ans=0;
while(l<cnt&&d[l]+d[cnt]<k) ++l;
while(l<cnt&&k-d[l]>=d[l])
{
int D1(look(l+1,k-d[l])),D2(look2(l+1,k-d[l]));
if(D2>=D1) ans+=D2-D1+1;
++l;
}
return ans;
}
void dfs(int x)//分治函数也改一下
{
use[x]=1,ans+=GET_ANS(x,0);//当前点答案
for(int i=h[x];i;i=c[i].x)
{
int y=c[i].y;
if(use[y]) continue;//防止找父亲
ans-=GET_ANS(y,1);//去掉满足在一个子树条件的不合法答案
Siz=siz[y],rt=0;
GET_ROOT(y,x),dfs(rt);//找下一个重心
}
}
这样答案就对了写丑了就不怪我了
-
复杂度
每次处理找树的重心,保证递归层数不超过$\log n$,dfs求距离复杂度是$O(n)$,这里处理答案是$\log n$,所以这个题总复杂度是$O(n\log^2n)$的……?反正过几万的数据是绰绰有余的(逃
补充:经$Aufun$大爷嘲讽教导后,因为有的题可以用桶排序,所以复杂度可以降到$O(\log n)$
当然有的题桶开不下必须$sort$了QAQ我一直用sort竟然没被卡

